links:
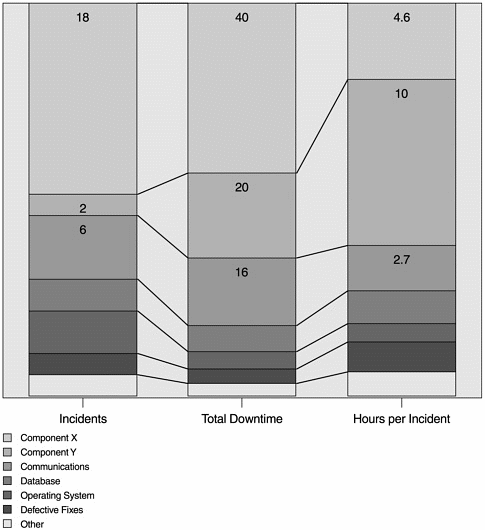
Illustration
1: Incidents of Outage, Total Downtime, and Hour per Incident by
Software Component
Mean Time Between Changes (MTBC)
Mean Time To Change (MTTC)
Also
called "time from concept to cash".
Important to: Everyone, especially the CEO, CIO and CTO.
Definition:
How long does it
take a new average feature, idea, fix or any other kind of change to
get into a paying customer's hands, in production, from the moment
of inception in someone's mind. MTTC is what it takes you from the
moment you see an opportunity until you can actually utilize it. The
faster MTTC is, the faster you can react to market changes.
How to measure:
We start
counting from moment of the change's inception in someone's head
(Imagine a marketing person coming up with a competing idea to that
of a competitor's product, or a bug being reported by a customer)
One way to capture and measure mean time to change is by doing a value streaming exercise, as we will touch on in a later chapter in this book.
Expected Outcome: MTTC should become shorter and shorter as Dev maturity grows.
Common Misunderstandings:
MTTC
is not the same as the often cited "Change lead time"
as proposed in multiple online publications.
Change Lead time only counts the time from the start of development of a feature, when real coding begins.
MTTC will measure everything that leads up to the coding as well, which might include design reviews, change committees, budgeting meetings, resource scheduling and everything that stands in the way of an idea as it makes its way into the development team, all the way through to production and the customer.
From a CEO, CIO and CTO view , MTTC is one of the most important key metrics to capture. Unfortunately, many organizations today do not measure this.
System Reliability: The probability that a system, including all hardware, firmware, and software, will satisfactorily perform the task for which it was designed or intended, for a specified time and in a specified environment.
System Availability
Total Hours of Downtime
With regard to in-process data, generally those at the back end (e.g., testing defects) are more reliable than those at the front end (e.g., design reviews and inspections). To improve data reliability, it is important to establish definitions and examples (e.g., what constitutes a defect during design reviews). Furthermore, validation must be an integral part of the data collection system and should be performed concurrently with software development and data collection.
Reliability, Availability, and Defect Rate
Reliability and availability certainly support each other. Without a reliable product, high availability cannot be achieved. The operational definition of reliability is mean time to failure (MTTF). For the exponential distribution, the failure rate (or better called the instantaneous failure rate) (l) is constant and MTTF is an inverse of it. As an example, suppose a company manufactures resistors that are known to have an exponential failure rate of 0.15% per 1,000 hours. The MTTF for these resistors is thus the inverse of .15%/1000 hours (or 0.0000015), which is 666,667 hours.
The F in MTTF for reliability evaluation refers to all failures. For availability measurement of computer systems, the more severe forms of failure (i.e., the crashes and hangs that cause outages) are the events of interest. Mean time to system outage, a reliability concept and similar to MTTF calculation-wise, is a common availability measurement. As an example, if a set of systems has an average of 1.6 outages per system per year, the mean time to outage will be the inverse of 1.6 system-year, which is 0.625 years.
As discussed earlier, in addition to the frequency of outages, the duration of outage is a key element of measuring availability. This element is related to the mean time to repair (MTTR) or mean time to recovery (average downtime) measurement. To complete the example in the last paragraph, suppose the average downtime per outage for a set of customers was 1.5 hours, the average downtime per system per year was 2.3 hours, and the total scheduled uptime for the systems was 445,870 hours, the system availability would be 99.98%.
Because of the element of outage duration, the concept of availability is different from reliability in several aspects. First, availability is more customer-oriented. With the same frequencies of failures or outages, the longer the system is down, the more pain the customer will experience. Second, to reduce outage duration, other factors such as diagnostic and debugging tools, service and fix responsiveness, and system backup/recovery strategies play important roles. Third, high reliability and excellent intrinsic product quality are necessary for high availability, but may not be sufficient. To achieve high availability and to neutralize the impact of outages often requires broader strategies such as clustering solutions and predictive warning services. Indeed, to achieve high availability at the 99.99% (52.6 minutes of downtime per year) or 99.999% level (5.2 minutes of downtime per year), it would be impossible without clustering or heavy redundancy and support by a premium service agreement. Predictive warning service is a comprehensive set of services that locally and electronically monitor an array of system events. It is designed to notify the customer and the vendor (service provider) of possible system failures before they occur. In recent years several vendors began offering this kind of premium service as a result of the paramount importance of system availability to critical business operations.
Over the years, many technologies in hardware and software have been and are being developed and implemented to improve product reliability and system availability. Some of these technologies are:
Redundant array of inexpensive disks (RAID)
Mirroring
Battery backup
Redundant write cache
Continuously powered main storage
Concurrent maintenance
Concurrent release upgrade
Concurrent apply of fix package
Save/restore parallelism
Reboot/IPL (initial program load) speed
Independent auxiliary storage pools (I-ASP)
Logical partitioning
Clustering Remote cluster nodes
Remote maintenance
Where data breakout is available, of the outages affecting system availability, software normally accounts for a larger proportion than hardware. As the Business Week report (1999) indicates, a number of infamous Web site and server outages were due to software problems. Software development is also labor intensive and there is no commonly recognized software reliability standard in the industry.
Both reliability (MTTF) and defect rate are measures of intrinsic product quality. But they are not related in terms of operational definitions; that is, MTTF and defects per KLOC or function point are not mathematically related.
In the software engineering literature, the two subjects are decoupled. The only relationship between defect levels and ranges of MTTF values reported in the literature (that we are aware of) are by Jones (1991) based on his empirical study several decades ago. Table 13.3 shows the corresponding values for the two parameters.
Jones's data was gathered from various testing phases, from unit test to system test runs, of a systems software project. Size of the project is a keyvariable because it could provide crude links between defects per KLOC and total number of defects, and therefore possibly to the volume of defects and frequency of failures. But this information was not reported. However, this relationship is very useful because it is based on empirical data on systems software. This area clearly needs more research with a large amount of empirical studies.
Table Association Between Defect Levels and MTTF Values
|
Defects per KLOC |
MTTF |
|
More than 30 |
Less than 2 minutes |
|
2030 |
415 minutes |
|
1020 |
560 minutes |
|
510 |
14 hours |
|
25 |
424 hours |
|
12 |
24160 hours |
|
Less than 1 |
Indefinite |
The same Business Week report ("Software Hell," 1999) indicates that according to the U.S. Defense Department and the Software Engineering Institute (SEI) at Carnegie Mellon University, there are typically 5 to 15 flaws per KLOC in typical commercial software. About a decade ago, based on a sample study of U.S. and Japanese software projects by noted software developers in both countries, Cusumano (1991) estimated that the failure rate per KLOC during the first 12 months after delivery was 4.44 in the United States and 1.96 in Japan. Cusumano's sample included projects in the areas of data processing, scientific, systems software, telecommunications, and embedded/real time systems. Based on extensive project assessments and benchmark studies, Jones (2001) estimates the typical defect rate of software organizations at SEI CMM level 1 to be 7.38 defects per KLOC (0.92 defects per function point), and those at SEI CMM level 3 to be 1.30 defects per KLOC (0.16 defects per function point). For the defect rates per function point for all CMM levels, see Jones (2000) or Chapter 6 in which we discuss Jones's findings. Per IBM customers in Canada, this writer was told that the average defect rate of software in Canada a few years ago, based on a survey, was 3.7 defects per KLOC. Without detailed operational definitions, it is difficult to draw meaningful conclusions on the level of defect rate or failure rate in the software industry with a certain degree of confidence. The combination of these estimates and Jones's relation between defect level and reliability, however, explains why there are so many infamous software crashes in the news. Even though we take these estimates as "order of magnitude" estimates and allow large error margins, it is crystal clear that the level of quality for typical software is far from adequate to meet the availability requirements of businesses and safety-critical operations. Of course, this view is shared by many and has been expressed in various publications and media (e.g., "State of Software Quality," Information Week, 2001).
Based on our experience and assessment of available industry data, for system platforms to have high availability (99.9+%), the defect rate for large operating systems has to be at or below 0.01 defect per KLOC per year in the field. In other words, the defect rate has to be at or beyond the 5.5 sigma level. For new function development, the defect rate has to be substantially below 1 defect per thousand new and changed source instructions (KCSI). This last statistic seems to correlate with Jones's finding (last row in Table 13.3). To achieve good product quality and high system availability, it is highly recommended that in-process reliability or outage metrics be used, and internal targets be set and achieved during the development of software.
Before the product is shipped, its field quality performance (defect rate or frequency of failures) should be estimated based on the in-process metrics.
In addition to reducing the defect rate, any improvements that can lead to a reduction in the duration of downtime (or MTTR) contribute to availability. In software, such improvements include, but are not limited to, the following features:
Illustration
1: Incidents of Outage, Total Downtime, and Hour per Incident by
Software Component